1. Text embeddings are generated for the open-ended responses using an AI embeddings model.
2. A k-means cluster analysis is conducted on the responses.
3. The k-means model is used to obtain a random sample of open-ended responses from each cluster.
4. A category name is generated for each sample using a generative AI model.
5. The k-means categories are replaced with the new category names and added to the dataset.
It’s also important to emphasize that you should review and validate the category names (and associations with open-ended responses) since an AI model cannot be held responsible for its work.
The maximum upload size is 100MB. The number of rows and columns can vary based on the number of numeric variables and the number of levels within nominal variables.
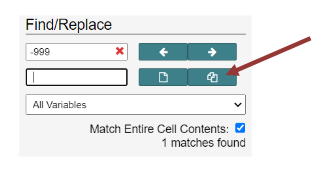
Intellectus uses blanks for all missing data. If your data set has -999, -1, NA, or other values or symbols to indicate missing data, go to the Management tab, Click Edit data, then Find/Replace. Enter missing data symbol or number in Find/Replace, add a blank space in the Replace, and click “Match entire cell contents,” then click the “Replace All” icon indicated by the red arrow below.
Here’s the procedure to recode multiple variable(s):
- Select Recode multiple;
- Select New measurement (e.g., Scale);
- Click variables to be recoded (Hint: recode group of similar questions at a time; e.g., q6_1 through q6_4), then click Continue;
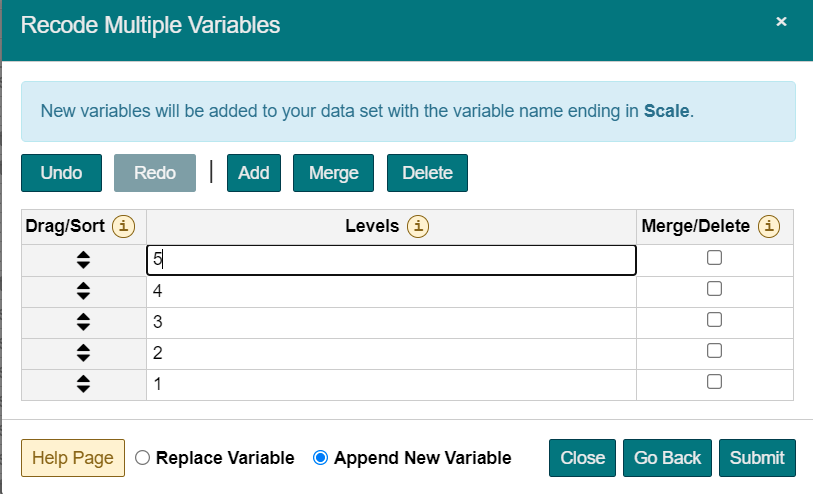
- Ensure that the order is correct. That is, drag levels from Fig 1 order to Fig 2 order.
Fig 1.
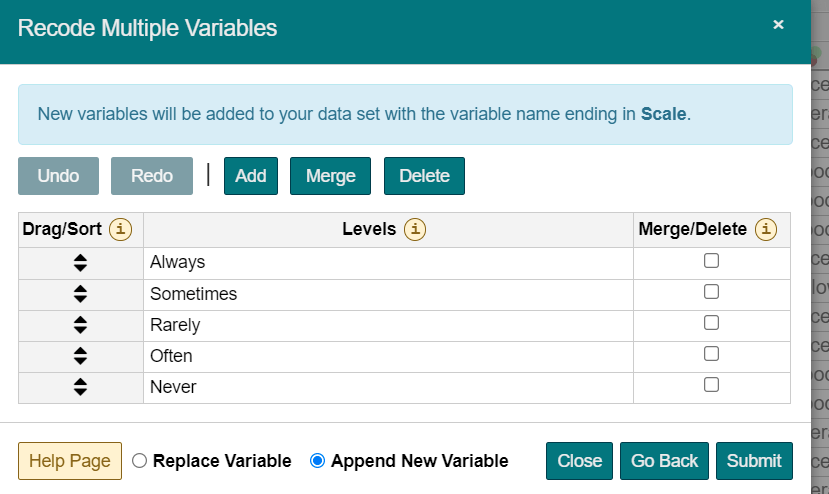
Fig 2.

- Once the correct order is properly sorted, then replace Levels names with numbers (e.g., from Never-Always to 1-5, respectively);
- Click Submit.
Intellectus does not support uploading data spread out over multiple tabs in Excel. In order to have all your data upload, you will need to combine it all onto the first tab. There are two ways to do this depending on whether you have matched case data or independent samples.
Matched-Case Data
Matched-case data is when you have data for the same subjects in each group. Each observation will have a “Subject ID” that you could use to match rows across multiple samples. Combining matched-case data involves pasting the columns side-by-side and matching them by ID. Let’s say we have matched-case data for each month on a new tab. We can copy the columns of each tab and match up the “Subject IDs” and paste them in the data on the first tab. The end result will look something like this:

Independent Samples Data
If you have independent samples, where each observation is a different subject, you will need to create a grouping variable instead. Let’s go with the same example above, so we have some measurement by month, where each tab is a different month on independent samples. Putting the data onto one tab will look like this:

Data can be structured in many ways, depending on which analysis is conducted. Intellectus has numerous examples of how to arrange data. Go to Projects tab, select Create Project/ Upload Dataset, then select Choose an Example Dataset. Then select the dataset from Suggested Analysis for the analysis you want to conduct, look at the variables for that analysis, and mirror that data format.
Intellectus Statistics™ has been designed to allow you to perform data management tasks while utilizing the software. After you first upload your data, you can verify the Level of Measurement for each of your variables, and can change the level by selecting the desired option from the appropriate drop down menu and following the subsequent instructions. The Manage Your Data page also allows you to perform further management tasks, including Reverse Coding, Computation of Composite Scores, Removal of Univariate Outliers, Removal of Multivariate Outliers, Transformation, and Multiple Imputation. To learn more about each of these options, simply scroll over the desired task and a pop-up window will provide more information. After you have performed your data management tasks, you have the option to download an updated data set that will reflect any changes you made.
You can convert your data in CSV format by entering it into a Microsoft Excel file, then selecting the “CSV (Comma delimited)” option from the Save as type drop down menu when saving your file.
Intellectus Statistics uses two methods of imputation, both described in the book Data Analysis Using Regression and Multilevel/Hierarchical Models by Andrew Gelman and Jennifer Hill. For Nominal and Ordinal variables, the missing values are imputed by randomly sampling from the observed categories. For Scale variables, a type of regression imputation is used. First, the missing values are imputed using the predicted values from the regression (the mean in this case). Last, a random amount is added to each imputed value based on the prediction error.
The data view in Data Tools only shows the first 500 observations. To view and manage the entire data set, click Edit Data option under Data Tools.