I have a quantitative analysis bias—I think everyone needs statistical literacy to function in society. To be an intelligent consumer of news you must know about fractions and percentages; yet, unfortunately, many citizens do not have these basic skills. That’s where educational technology comes into play. Educational technology learning tools have evolved from the abacus, to whiteboards, to computers, with tons of technology in between and in front of us. These technologies have allowed us to be more confident in what we’re doing, to learn with ease, to learn faster, and to learn less expensively.
Data science technology has evolved too. Statistical software over the past 40 years, particularly IBM SPSS and SAS, have dominated the education and business markets with smart, easy to use graphical display and quantitative analytics. Other companies like Tableau have engaged us in data visualization, and Survey Monkey and Qualtrics have allowed us to create questionnaires, describe data, and create basic tables.
But data science is much more than graphical display and quantitative analytics. I fear that too much time was spent learning the programs, interpreting the output, and presenting the findings, and less attention to thinking about the research methodology, examining the strengths and limitations of a study’s design, thinking about who is electing to be a respondent and who is electing to not participate, how attrition plays a role in the findings, and how to manage the data. On the back-end, more time and energy should have been given to what the results mean for theory and practice, and how those results fit into the historical context of the subject, and what generalizations, if any, can be made.
If, as a mentor said, that educational technology is about extending human capabilities to be more effective and efficient, then there is a lot more that can be done on the cleaning, conducting, interpreting, and presenting of analyses, leaving more time for the front and back-end of the research enterprise. Intellectus Statistics is playing a role in that effective and efficient technology.
Intellectus Statistics has a patent-pending process of cleaning the data, comprehensively assessing a tests’ assumptions, interpreting the data, then writing the findings in plain English all in about .125 milliseconds. Effectiveness—doing the right things—is improved by having all of a test’s assumptions thoroughly assessed and analyses accurately conducted and interpreted, conducting post-hoc tests, interpretations with Bonferroni corrections, all parsimoniously written in English narrative, every time. Efficiency—doing things with the least waste of time and effort—is improved by automating statistician-like decisions, automatically generating additional tests, tables, and figures, when necessary, and not having to copy, paste, edit, and format tables and figures.
I’m interested in your thoughts about educational technology, data science, Intellectus Statistics, and where the data science field might go from here.
I was presenting Intellectus Statistics to an international educational marketer recently who asked about the interpretation, “shouldn’t students write it themselves?” he asked. My first response is “sure, don’t use the interpretation, just the raw output.” Then I kind of scratch my head and think, “how is the current mode of learning statistics working for all of those undergrads, masters, and professional degrees?” At the doctorate level, the answer is not very well. Through the years I’ve noticed a trend of “dumbing down” of statistics (to descriptive or qualitative) in many doctoral level studies, and for undergrads and master’s levels, even worse. Houston, we have a problem! Intellectus is a response to this problem.
Intellectus is ideally suited to two primary populations: students learning statistics and those needing a results chapter draft. For students, that use Intellectus Statistics, the application does three things no other software does. First, it teaches students what assumptions should go into the analyses. Second, it confirms students are accurately interpreting the assumptions, analyses, and post-hoc tests. The immediate validation of their thinking, lowers anxiety, and builds confidence. Third, it teaches students how to report statistical output in a scholarly fashion and how to present in APA style. Statistics instructors have said it saves them office hour time and students are not bogged down by learning a particular stats program—then having to learn how to interpret that specific program’s output to properly report their findings.
The second population Intellectus is ideally suited for are those needing a results chapter draft. Dissertations, theses, poster presentations, and faculty, all appreciate the ability to generate a draft in seconds rather than hours and weeks. The application is a great time saver that allows users to spend more time thinking about the theoretical and practical implications of their findings, rather than trudging through the formatting process.
There’s another benefit—the cost. Intellectus is often half the price of legacy software. Given the cost of the application, interpreted output in APA style, glossary of terms and symbols, and raw output, the value is clear. Why use Intellectus Statistics? The real question you should be asking yourself is why not!
Intellectus Statistics is a powerful, cloud-based, less expensive, teaching and learning tool as an alternative to IBM-SPSS.
IBM-SPSS is a data analysis tool used by statisticians for predictive modeling, data mining, big data analytics, and some reporting. SPSS has a data tab, a syntax tab, and an output tab. To conduct a regression and assess assumptions, a user may use these four windows. As a data scientist, there are numerous decisions to be made. However, observing students for 25 years, students do often struggle with these options.
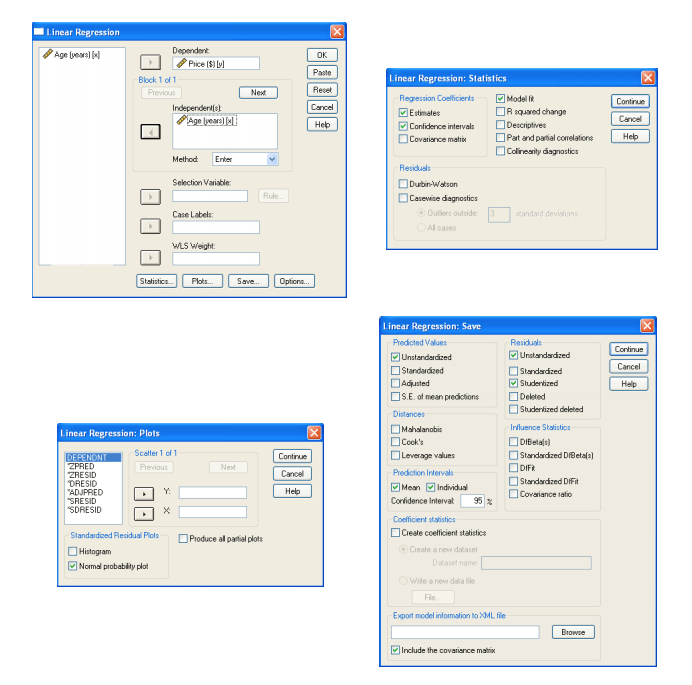
After conducting the analyses, users will be provided output. Some of the information is important to the data scientist, but not for students. For example, students reporting regressions do not use the sum of squares or mean square in reporting the regression.
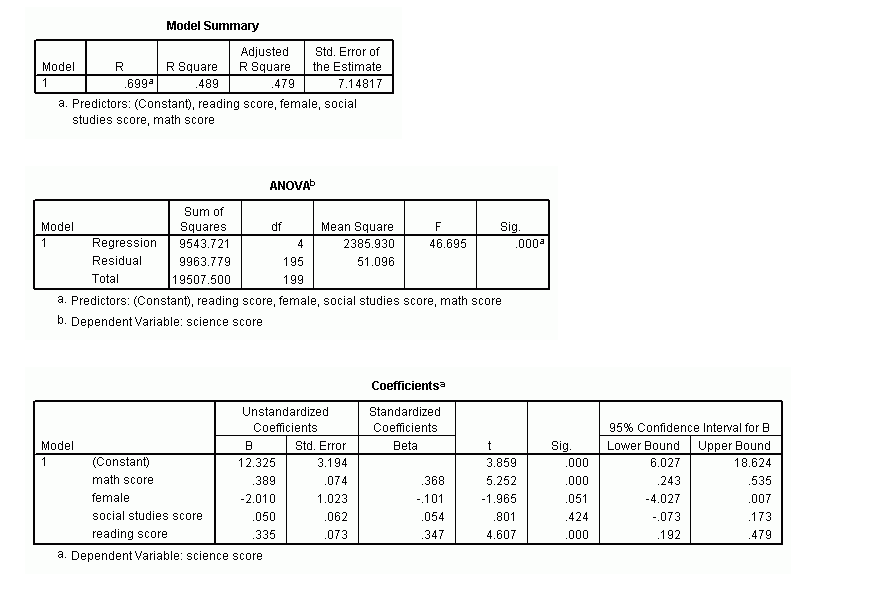
The user then needs to accurately interpret the output and format the results in a Word document. Again, most data scientists would have no trouble in the interpretation, but students struggle enormously figuring out what the impact of a beta coefficient is on the dependent variable.
Comparatively, Intellectus Statistics has a much easier user interface that differs from IBM-SPSS, making it an easy to use SPSS alternative. Below is Intellectus’ regression interface: simply select the DV and the IV.
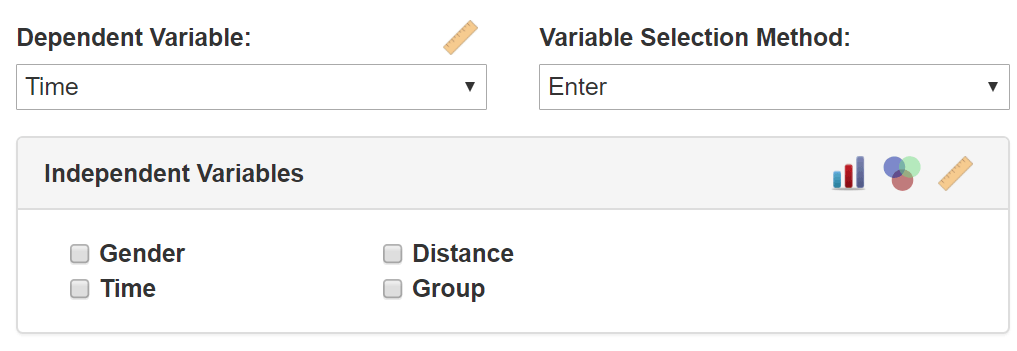
But wait, how about the assumptions, request of the estimates, and plots? Intellectus Statistics automatically preloads those requests and executes those preloads when the regression is conducted. Intellectus is more than an alternative because it does so much more. Intellectus interprets the analysis and presents that interpretation in plain English prose and formats APA tables.

Intellectus Statistics is similar to SPSS in the ability to enter or upload data, and in the analyses it conducts. Below is a list of the analyses that Intellectus Statistics conducts.
- (Multiple) Linear Regression
- Binary Logistic Regression
- Multinomial Logistic Regression
- Ordinal Logistic Regression
- Hierarchical Linear Regression
- Descriptive Statistics
- Cronbach’s Alpha
- Pearson correlations
- Kendall Correlation
- Spearman correlations
- Partial correlation
- ANOVA
- ANCOVA
- Repeated-measures ANOVA
- 1-between, 1-within ANOVA
- MANOVA
- MANCOVA
- One Sample t Test
- Paired Samples t Test
- Independent Samples t Test
- Chi-square test of Independence
- Chi-Square Goodness of Fit Test
- McNemar’s Test
- Wilcoxon Signed Rank Test
- Friedman Test
- Mann-Whitney U Test
- Kruskal-Wallis Test
- Mediation
- Moderation
- Hierarchical Linear Model
- Survival Analysis
Intellectus Statistics also has a lot of built-in features that differ from IBM-SPSS.
- Interpreted output. In both the output viewer and in the downloaded document, Intellectus Statistics™ interprets the statistical assumptions and analysis findings, and generates tables and figures that correspond to the assumptions and output. This innovation was crucial in reducing statistics anxiety and presenting the student with all the information needed to go from data upload to statistical understanding.
- Projects tab. The Projects tabs allows the ability to create and save projects. Projects save any data, managed data, and analyses previously conducted so you log back in and pick up where you left off. It also means that collaboration can occur by colleagues.
- Logical user interface. Intellectus Statistics™ walks students through a logical step-by-step process that is sequential and easy. Data upload, to manage data, visualize data, conduct analyses, and review the interpreted output.
- Level of measurement reminders. Level of measurement is crucial to the conducting of analyses. The tool reminds students how to define levels of measurement and gives examples on the levels validation page.
- Pre-selects variables’ level of measurement for analyses. The tool lets you select only the variable appropriate for a particular statistical test. For example, when selecting an ordinal regression, only ordinal variables for the criterion will be available for selection.
- Preloads assumptions. Statistical techniques often have several assumptions to consider prior to interpreting analyses, so we’ve programmed to have assumptions such as normality and homoscedasticity pre-loaded without any intervention of the student.
- Preloads post-hoc tests. The tool preloads post-hoc tests and even corrects the alpha level in the interpretation. For example, if an ANOVA is statistically significant, Tukey post-hoc tests will be conducted, and a Bonferroni correction applied to the alpha level and interpretation.
- Non-parametric equivalent test is automatically conducted. When the parametric assumptions of a test are violated, the non-parametric equivalent test is automatically conducted and presented.
- Automated dummy code. When conducting some analyses, ordinal and nominal level variables need to be dummy coded and a reference variable selected. For example, when a regression analysis is selected, the nominal and ordinal variables are automatically dummy coded.
- Centered interaction terms. For moderation analyses, the tool mitigates multicollinearity by automatically centering terms before creating the interaction term.
- Interesting data visualization. The plots included in the tool are much more interesting and interactive than most plotting platforms. From including different groupings, to changing the look of the plot, to easy-to-print and save features, our visualization platform motivates students to engage with their data.
- Editable APA tables and scalable figures. Intellectus Statistics™ is programmed to know what tables and figures to generate for each statistical test. Its dynamic in that it generates more or less tables and figures based on the statistics and their significance levels. For example, if an ANOVA is statistically significant, post-hoc statistics tables will be generated. And these tables are editable, and figures are scalable, making it easy to change titles or labels.
- Glossary. For every test used, a glossary defining the terms and symbols is provided in the beginning of the document.
- APA references. All scholarly documents need to cite the intellectual contribution of others’ thoughts. All cited work is referenced in a reference section in APA format at the end of the document.
- Excel files accepted. While most everyone is familiar with Excel, the tool accepts Excel files with .xlsx, .xls, .sav, and .csv extensions.
- Web-based. As a web-based tool, students no longer have to struggle with downloading and installing software. Intellectus Statistics works with any operating system and the only requirement is internet access. This mode of delivery makes the tool accessible anywhere and the student has instantaneous access to the newest statistical techniques and functionality. Sometimes software that is built for a PC is clunky on a Mac. Users will enjoy the smoothness of our web-based application on any operating system.
Intellectus Statistics is a superior alternative to IBM-SPSS based on the features listed below.
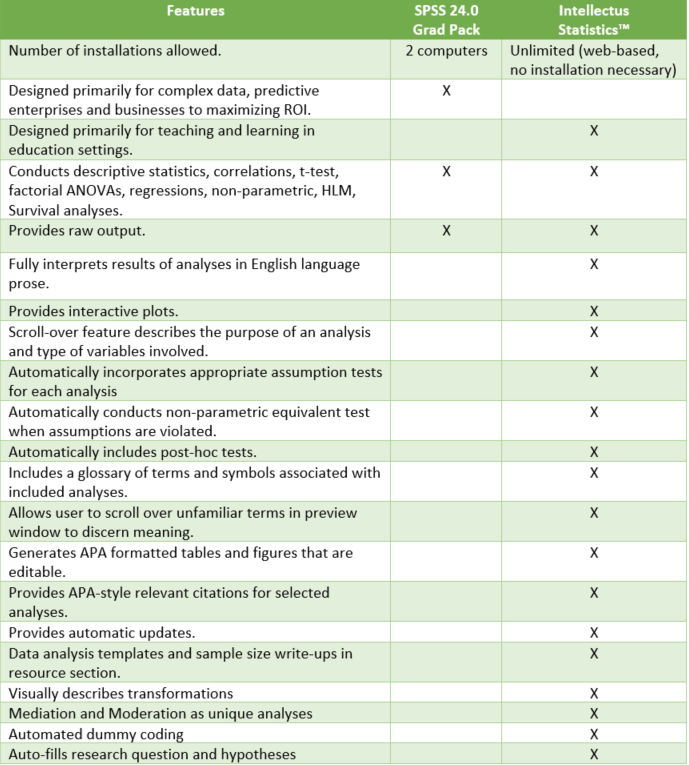
At the end of the day, IBM-SPSS is designed for statisticians and businesses, and also is used for educational purposes. Unfortunately, until Intellectus Statistics came along, there was no adequate statistical package alternative for students (there is Minitab and SAS, but really provided more of the same). For business and researchers, while Intellectus has many similarities to IBM-SPSS, many data scientists would want to stick with SPSS and its flexibility. Conversely, for educational purposes, there is no question that Intellectus Statistics is a better alternative, not only from a data analysis perspective, but from a teaching and learning perspective. Students historically struggle with interpretation and package-specific learning—Intellectus Statistics overcomes those barriers.
Introduction
Over decades of statistical consulting, school administrators and graduate students consistently needed comprehensive quantitative analyses and quality reports without having to be statisticians. They needed the right tool to support their data management, selection of analyses, and understanding of the findings.
Market Drivers
These individuals have a clear idea of their variables, research questions, and they need answers quickly. They need answers without having to have a degree in statistics. While their need for an easy to use program is great, the technology has not been available. Given limited staff, and time, to conduct analyses, they need a program that delivers a presentation-ready document with descriptive and sophisticated analyses, along with publication quality graphics.
Intellectus Statistics’ Solution
Intellectus Statistics is a technological innovation. This package is easy to use, allows for data management, offers common plots, interprets output in plain English, and downloads into Word. Intellectus also comes with live support of a statistician should additional questions about data plans, sample size, using the program, and understanding the output arise.
Benefits
One benefit of Intellectus is in its automation. The software has built-in “skills.” For example, when an analysis is selected, the assumptions of that analysis is preloaded, if assumptions are violated, the non-parametric equivalent is automatically conducted. Appropriate tables and figure are automatically produced. The program guides you to use the right variables in the right analysis.
Time savings in the second big benefit of Intellectus. Many projects that typically take 2 weeks can be accomplished within 2-hours. This is accomplished because the program drafts the findings in English sentences in seconds. This helps administrators and students make decisions about their analysesquickly.
Money is the third big benefit. School districts’ administrators and students don’t have to hire out statisticians to conduct, interpret, and draft findings—it’s all part of the program.
Case study 1: Grant recipient Needed Analyses and Figures. A grant recipient sought to describe English and Math scores of their institution and examine these scores by ethnicity and time to graduate. In less than 5 minutes, the following figures and analyses were generated.
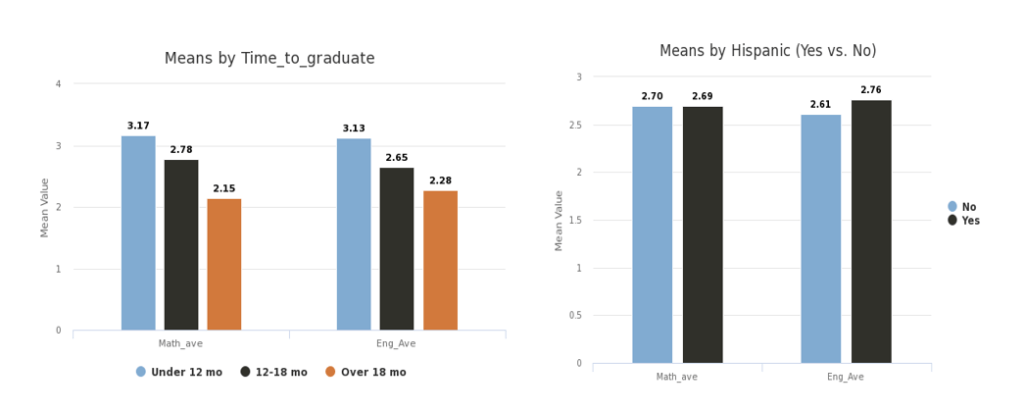
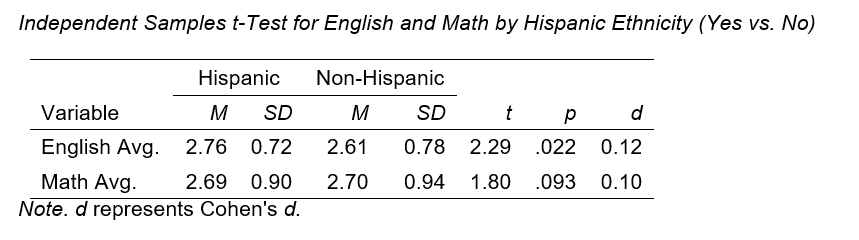
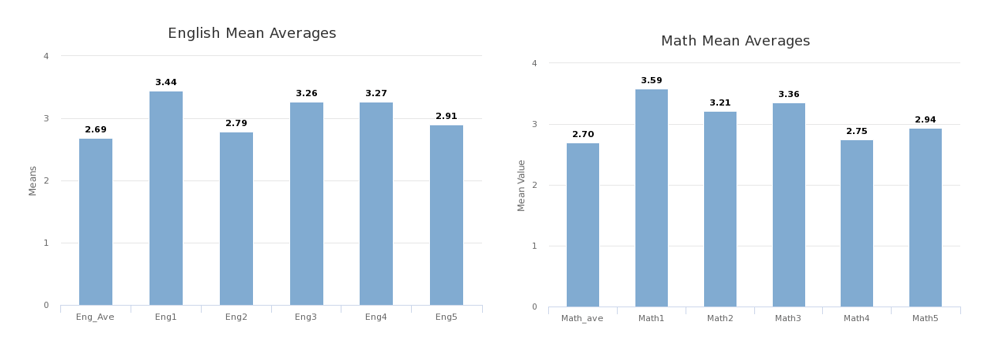
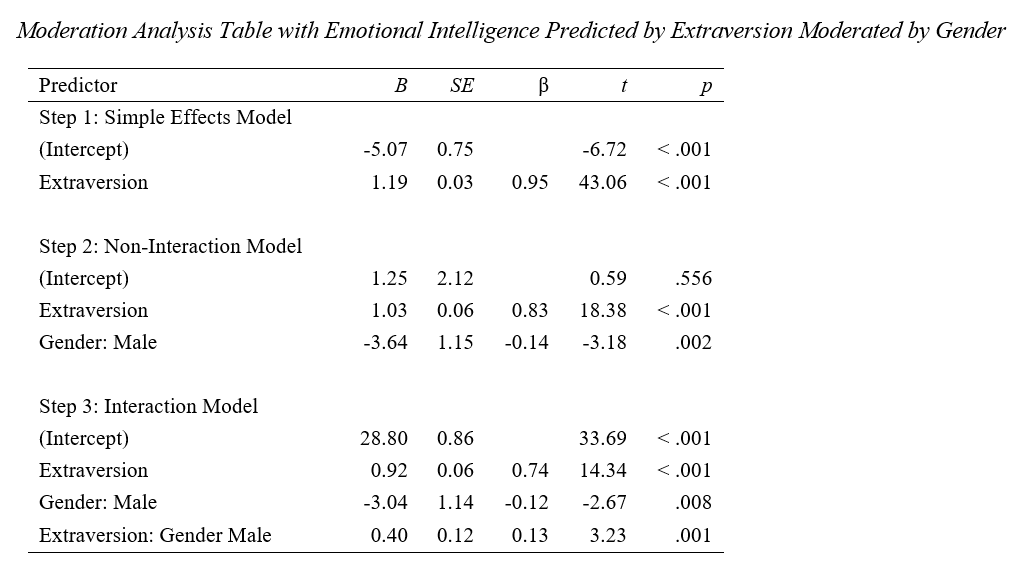
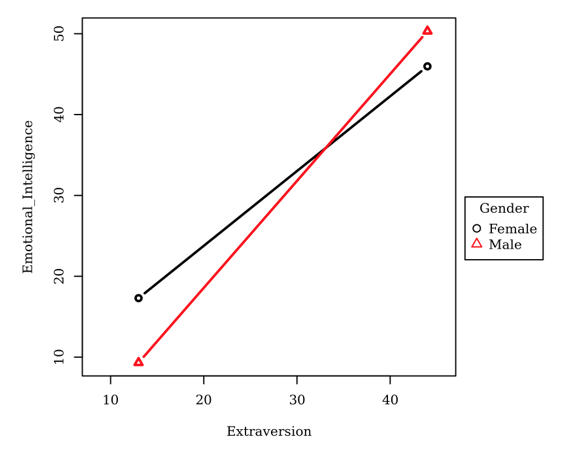
Case study 2: Doctoral Candidate Needed a Moderation Analysis. A dissertation student sought to examine whether gender moderated the relationship between Extraversion and Emotional Intelligence.
The following verbiage, table, and figure were generated in seconds.
“…Since Extraversion significantly predicted Emotional Intelligence in the simple effects model (condition 1) and the interaction model explained significantly more variance of Emotional Intelligence than the non-interaction model (condition 2), then moderation is supported…This suggests that moving from the Female to Male category of Gender will cause a 0.40 increase in the slope of Emotional Intelligence on Extraversion….”
Intellectus—SPSS Comparison
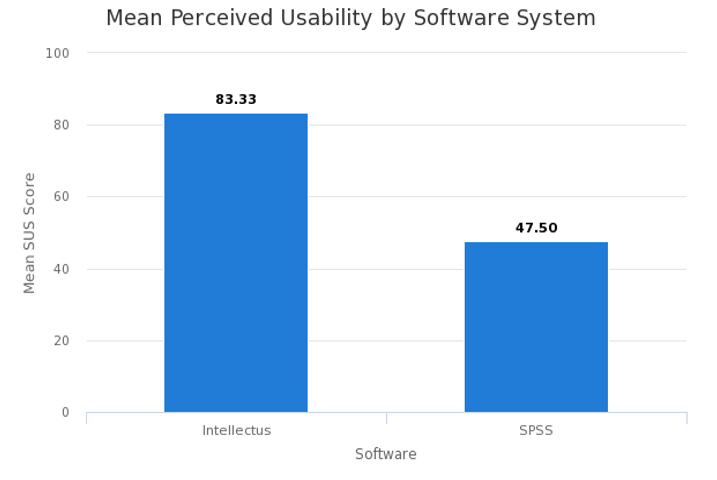
A 2015 study (Orfanou, Tselios, and Katsanos, 2015) reported that “perceived usability greatly affects students learning effectiveness and overall learning experience.” The System Usability Scale (SUS) is a widely used, well-researched survey for perceived usability evaluation. The SUS is a self-reported 10-item Likert scale questionnaire that measures overall perceived reliability. Bangor, Kortum, and Miller (2008) cited SUS as a highly robust tool for measuring perceived usability. The perceived usability scores range from zero to 100, where scores under 50 indicate unacceptable usability, 51 to 70 indicate marginal acceptability, and scores above 70 indicate acceptable usability (Albert, W., & Tullis, T, 2013).
In a recent study, Chen, Moran, Sun, and Vu (2018) compared SPSS to Intellectus Statistics (IS) overall Perceived Usability using the SUS scores. The findings indicated that participants rated IS significantly more usable compared to SPSS. The SUS scores for IS level of usability (M = 83.33, SD = 11.74) is considered acceptable, while the SUS scores for SPSS (M = 47.50, SD = 15.67) were statistically lower and considered unacceptable.
Conclusion
The goal is to enable every school administrator and graduate student to easy conduct analyses and have a deeper understanding of findings. Intellectus is a breakthrough technology that automates processes, saves time in drafting findings, saves money in outsourcing work, and has very high perceived usability.
Intellectus is Latin for comprehension. Intellectus Statistics is designed to support understanding, where administrators and students can make decisions from their data analyses in seconds.
References
Albert, W., & Tullis, T.: Measuring the user experience: collecting, analyzing, and presenting usability metrics. Newnes (2013).
Bangor, A., Kortum, P. T., & Miller, J. T.: An empirical evaluation of the system usability scale. Intl. Journal of Human–Computer Interaction, 24(6), 574-594 (2008).
Chen, A.C., Moran, S., Yuting Sun, Y., & Vu, K.L. (In press). Comparison of Intellectus Statistics and Statistical Package for the Social Sciences Differences in User Performance based on Presentation of Statistical Data. Proceedings of the 2018 Human Computer Interaction International conference.
Konstantina Orfanou, K., Tselios, N., & Katsanos, C. (2015). Perceived Usability Evaluation of Learning Management Systems: Empirical Evaluation of the System Usability Scale. The International Review of Research in Open and Distributed Learning (Vol 16, No.2).
In the first paragraph of your quantitative chapter 4, the results chapter, restate the research questions that will be examined. This reminds the reader of what you’re going to investigate after having been trough the details of your methodology. It’s helpful too that the reader knows what the variables are that are going to be analyzed.
Spend a paragraph telling the reader how you’re going to clean the data. Did you remove univariate or multivariate outlier? How are you going to treat missing data? What is your final sample size?
The next paragraph should describe the sample using demographics and research variables. Provide frequencies and percentages for nominal and ordinal level variables and means and standard deviations for the scale level variables. You can provide this information in figures and tables.
Here’s a sample:
Frequencies and Percentages. The most frequently observed category of Cardio was Yes (n = 41, 72%). The most frequently observed category of Shock was No (n = 34, 60%). Frequencies and percentages are presented.
Summary Statistics. The observations for MiniCog had an average of 25.49 (SD = 14.01, SEM = 1.87, Min = 2.00, Max = 55.00). The observations for Digital had an average of 29.12 (SD = 10.03, SEM = 1.33, Min = 15.50, Max = 48.50). Skewness and kurtosis were also calculated. When the skewness is greater than 2 in absolute value, the variable is considered to be asymmetrical about its mean. When the kurtosis is greater than or equal to 3, then the variable’s distribution is markedly different than a normal distribution in its tendency to produce outliers (Westfall & Henning, 2013).
Now that the data is clean and descriptives have been conducted, turn to conducting the statistics and assumptions of those statistics for research question 1. Provide the assumptions first, then the results of the statistics. Have a clear accept or reject of the hypothesis statement if you have one. Here’s an independent samples t-test example:
Introduction. An two-tailed independent samples t-test was conducted to examine whether the mean of MiniCog was significantly different between the No and Yes categories of Cardio.
Assumptions. The assumptions of normality and homogeneity of variance were assessed.
Normality. A Shapiro-Wilk test was conducted to determine whether MiniCog could have been produced by a normal distribution (Razali & Wah, 2011). The results of the Shapiro-Wilk test were significant, W = 0.94, p = .007. These results suggest that MiniCog is unlikely to have been produced by a normal distribution; thus normality cannot be assumed. However, the mean of any random variable will be approximately normally distributed as sample size increases according to the Central Limit Theorem (CLT). Therefore, with a sufficiently large sample size (n > 50), deviations from normality will have little effect on the results (Stevens, 2009). An alternative way to test the assumption of normality was utilized by plotting the quantiles of the model residuals against the quantiles of a Chi-square distribution, also called a Q-Q scatterplot (DeCarlo, 1997). For the assumption of normality to be met, the quantiles of the residuals must not strongly deviate from the theoretical quantiles. Strong deviations could indicate that the parameter estimates are unreliable. Figure 1 presents a Q-Q scatterplot of MiniCog.
Homogeneity of variance. Levene’s test for equality of variance was used to assess whether the homogeneity of variance assumption was met (Levene, 1960). The homogeneity of variance assumption requires the variance of the dependent variable be approximately equal in each group. The result of Levene’s test was significant, F(1, 54) = 18.30, p < .001, indicating that the assumption of homogeneity of variance was violated. Consequently, the results may not be reliable or generalizable. Since equal variances cannot be assumed, Welch’s t-test was used instead of the Student’s t-test, which is more reliable when the two samples have unequal variances and unequal sample sizes (Ruxton, 2006).
Results. The result of the two-tailed independent samples t-test was significant, t(46.88) = -4.81, p < .001, indicating the null hypothesis can be rejected. This finding suggests the mean of MiniCog was significantly different between the No and Yes categories of Cardio. The mean of MiniCog in the No category of Cardio was significantly lower than the mean of MiniCog in the Yes category. Present the results of the two-tailed independent samples t-test, and present the means of MiniCog(No) and MiniCog(Yes).
In the next paragraphs, conduct stats and assumptions for your other research questions. Again, assumptions first, then the results of the statistics with appropriate tables and figures.
Be sure to add all of the in-text citations to your reference section. Here is a sample of references.
References
Conover, W. J., & Iman, R. L. (1981). Rank transformations as a bridge between parametric and nonparametric statistics. The American Statistician, 35(3), 124-129.
DeCarlo, L. T. (1997). On the meaning and use of kurtosis. Psychological Methods, 2(3), 292-307.
Levene, H. (1960). Contributions to Probability and Statistics. Essays in honor of Harold Hotelling, I. Olkin et al. eds., Stanford University Press, 278-292.
Razali, N. M., & Wah, Y. B. (2011). Power comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling tests. Journal of Statistical Modeling and Analytics, 2(1), 21-33.
Ruxton, G. D. (2006). The unequal variance t-test is an underused alternative to Student’s t-test and the Mann-Whitney U test. Behavioral Ecology, 17(4), 688-690.
Intellectus Statistics [Online computer software]. (2019). Retrieved from https://analyze.intellectusstatistics.com/
Stevens, J. P. (2009). Applied multivariate statistics for the social sciences (5th ed.). Mahwah, NJ: Routledge Academic.
Westfall, P. H., & Henning, K. S. S. (2013). Texts in statistical science: Understanding advanced statistical methods. Boca Raton, FL: Taylor & Francis.